FAQs
Frequently Asked Questions
Q) How does EigenTrust work better than proprietary algorithms that developers can create themselves?
EigenTrust is about leveraging open data and honest algorithms. We want to make it easy for web3 developers to integrate reputation infrastructure for their applications, which is both sybil-resistant and context specific.
Here’s why proprietary algorithms for reputation don’t work for web3:
The cost to a project of custom-building reputation infrastructure is high, and the reward to having proprietary reputation infrastructure is small. Even in web2, most companies use Apache Solr, which is open-source infrastructure, for their rankings. So long as the cost to run EigenTrust computations is low, and the quality is good, there is little incentive to roll one’s own reputation infrastructure.
Another key question is whether projects would prefer to keep the data that goes into the reputation scores proprietary. Certainly web2 companies do this. But once you go down this route, you have to host the data on your own server; you are no longer permissionless, you are no longer censorship-resistant, you have a central actor in the middle. None of these are issues for web2 companies - they live in this world already. But all of this poses great risk for a web3 project. In practice, for projects like Lens/Farcaster with the follower/followee graph already on-chain/accessible, it would be natural for them to feed that data, that already exists on-chain, into an open-source reputation algorithm.
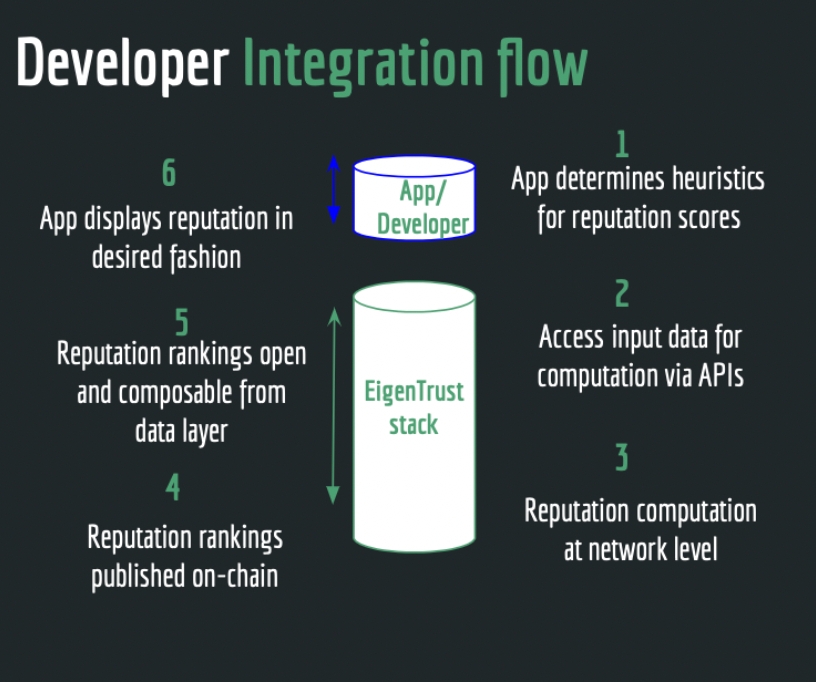
Q) What is the architecture of the protocol?
The foundational layer of the protocol is a decentralized computation network. The network performs the EigenTrust calculations and makes the reputation data available for developers to use in their applications. This layer will be designed to ensure a constraint free and optimized implementation of the power method which runs in polynomial time.
Another component of the protocol will involve a Data APIs layer which will enable developers to select the relevant data that needs to be ingested for reputation computation in their use case. Developers can choose to leverage any on-chain data or bring their off-chain data. This layer will also enable developers or their community to input the seed peers as well as their desired pairwise trust (reputation heuristic) to perform the EigenTrust computation. The results of the reputation computation will be published on a desired data infrastructure.
Q) Who are the target customers or users?
Our target customers include web3 application developers working on consumer marketplaces and products, web3 social protocol developers and third-party developers in an ecosystem who want to experiment and curate a variety of reputation heuristics on custom front-ends.
Almost every other consumer-facing developer who is leveraging on-chain data related to users/public keys will benefit from EigenTrust rankings. Further, network effects will start to accrue once developers start benchmarking reputation heuristics for their use case and start relying on EigenTrust computation for their rankings.
A new developer can bootstrap reputation of their community by composing many different EigenTrust scores across different use cases. For instance, for Optimism DAO to create their community reputation or ranking, they could use a combination of Uniswap reputation scores, community governance rankings and Optimism creator ranking.
Composability of reputation rankings across different contexts will drive more innovation and network effects that can power better search and discovery UX for applications.
Q) How will developers interact with EigenTrust protocol?
We will provide a developer interface/tooling for the following:
Choose existing on-chain data sources or hook off-chain APIs to enable required data ingestion for the EigenTrust computation
Based on the use case, input seed peer (benchmark for trustworthiness) and pairwise trust mechanism (reputation heuristic).Both of these are easily customizable by each developer, and can be modified in case context for reputation evolves
Computation results via registry smart contract.
Q) Where does the data you use for computing reputation come from? Where does it get stored?
The data to compute reputation can be ingested both via app APIs, or can be crawled from on-chain activity related to the use case. Developers don’t have to themselves manually index relevant on-chain data which will be used for EigenTrust computation. We plan to enable a data API layer, leveraging existing indexer solutions (subgraphs/custom APIs/dune), which makes on-chain data access easy. We will also enable a snapshot/storage solution.
Once developers populate the storage layer with the input data (along with its validity proof), they can then point EigenTrust to that dataset; validators independently fetch (and verify the authenticity of) the data from the storage layer.
Q) Can developers bring their own data to compute reputation scores?
Yes, developers can input their own data for generating their context specific reputation scores. They can also update their data sets based on community demands or if the context of reputation evolves. We want to enable an open trust computation and don’t constrain developers to choose a certain type of data to calculate reputation scores.
Additionally, we are also exploring how to enable EigenTrust computation on private data, using Zk-proofs. This will be especially helpful in use cases where developers don’t want to rely on open data/graphs and those where developers want to enable negative reputation while maintaining confidentiality of the participants.
Last updated